For the complete reading experience make sure to open the article in the browser.
Python article. Not sure starting the series is the right way to go forward. But one of the plans is to drop a few articles on Python and scraping in general. The main reason is that it’s a valuable skill set to have if you are doing lead gen on a side.
Not only for the lead gen. But if you are handy enough you could sell scraped data around for profit. Wondering where the real magic is?
Scraping industry pain points, any unsatisfied customer review (with your competitors) plus anything else that comes to your mind. The use case for Python is huge. Something we plan to cover in the long run.
Have zero experience with Python? Start with the article below.
We are not going to cover the setup part and how we are setting things up. The basics should be understood by reading the first Python article above. You will need additional libraries as well as webdriver and CRX files to pull this off.
Before we go any further keep in mind we are not experts in Python or coding. In each case feel free to modify the code provided to suit your requirements and needs.
We are sure there are more efficient ways to do this.
Below you will find a few ways to scrape Google Maps for leads. All with similar results. But with a different approach. Hard to say which one is the best one or most optimal.
Requirements Method #1
Additional libraries you will need.
pip install selenium
pip install keyboard
pip install pynput
Since we will be using selenium you will need a webdriver for it.
Make sure to save webdriver in the folder where your Python project is located - simplicity reasons.
CRX
“A CRX file is a compressed archive file that contains one or more Google Chrome browser extensions.”
Since our method is not as efficient as it used to be back in the day. You will need an additional download better said Chrome extension. We will be searching for a Chrome extension called “Instant Data Scraper”.
To download the CRX file go to the following website and copy/paste the link you grabbed from your extensions store. Hopefully, there is the same extension available on Firefox.
Once you download the CRX file → same principles as in the webdriver example → save it in the folder where your project is located.
Requirements Method #2
pip install pytest-playwright
playwright install
pip install pandas
“Poor Man” Scraping Google Maps - Method #1
Done with the boring stuff? Setup in the place? Perfect. Let’s get to a little less boring stuff. Before we go any further. You have to understand there were big changes when it comes to Big G (Google if you didn’t catch the reference).
The game is not as easy as it used to be. Almost impossible if you are not technical or you don’t have a “funny“ workaround as we do have. In each case let’s go over our method.
The first Python code you will find below was made to work with the Chrome and Chrome webdriver. In case you decide to do it with any other browser you will have to change it accordingly.
“Mouse coordinates” in our code below were based on 1080p resolution with display scaling set at 100%. Meaning if you have any option different you will have to change the code to fit your needs. The same goes for running Linux or Mac.
The easiest way to change the “mouse coordinates” is by using the code below. Find out where the required “buttons” you want to manipulate are located and apply those to your code.
How To Mouse Manipulation
from pynput import *
def get_coords (x, y):
print("Now at: {}".format((x, y)))
with mouse.Listener(on_move = get_coords) as listen:
listen.join()
Expected output:
You will notice that moving the mouse yields different mouse coordinates. The rest should be pretty self-explanatory.
Breakdown
As with most cases when it comes to Python. You will need libraries to make things go off the ground.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from pynput.mouse import Controller, Button
import keyboard as kb
import time
The next step is to set up Selenium and locate your webdriver and CRX. Make sure to edit this code in case you are not using Google Chrome. Because we want transparency we are going to be running Chrome in the background.
What do we mean by that? The entire process will be visible. It’s possible to do it all in the “background” (not visible). But that’s not the goal here. Since the majority will be doing this kind of automation for the first time.
EDIT: 29.08.2023
July Selenium update and new chromedriver policy messed things up for us. We had to change the code, so here is the update for all of you.
We are running a sleep option with different “sleep periods”. You will notice this later in the code. To be on the safe side it's always a good practice to include a 'buffer'. It’s not so important in this case. Remember this if you plan to take scraping seriously in the future.
#Marks how much time will it take before "next step". Adjust based on your needs
t1 = 3
t2 = 5
t3 = 10
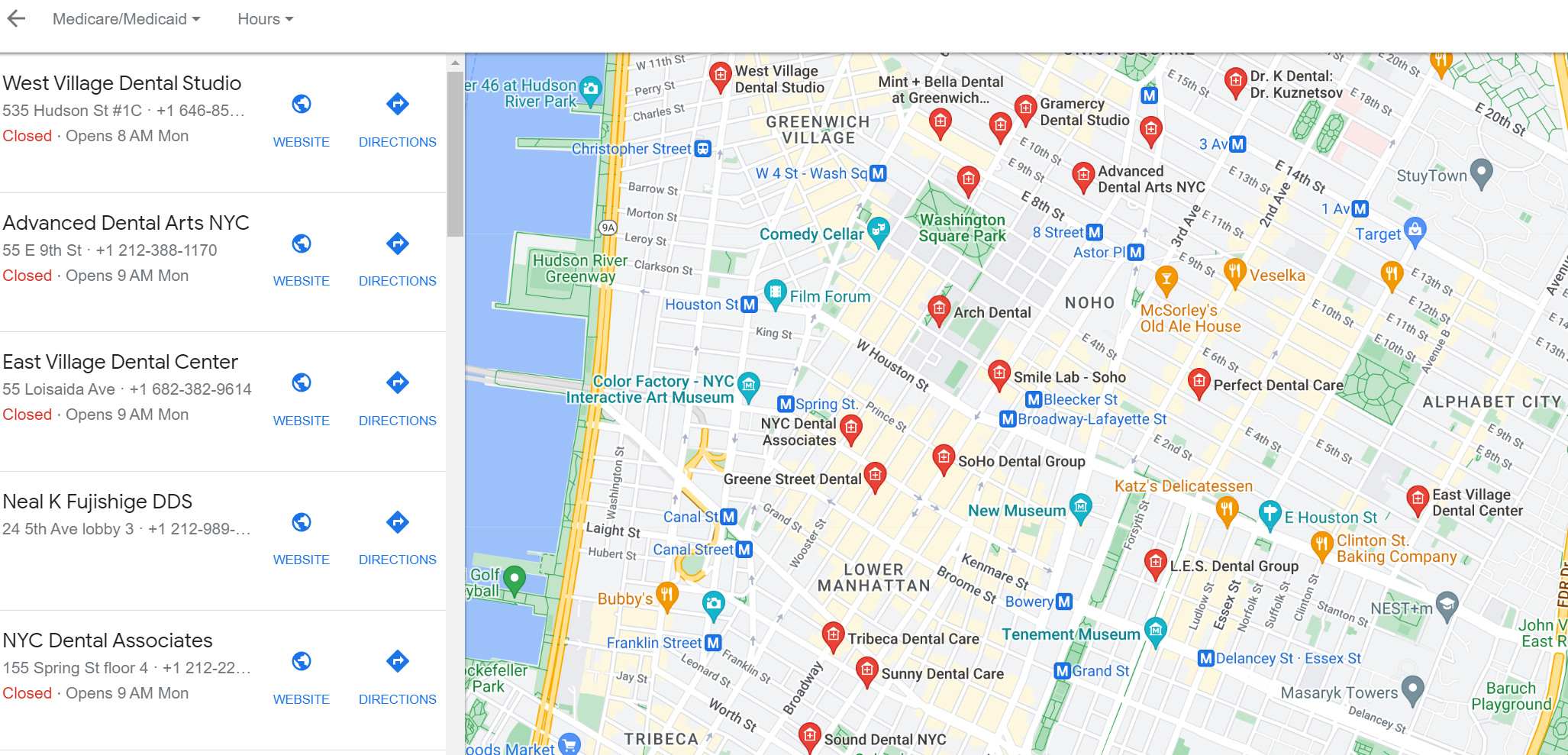
Url = driver.get is pointing at the Google Maps location we want. The easiest way for you to change the search term is by simply swapping out the wording inside of the code. Think of it in terms of Niche + Location. For even greater specificity → include the neighborhood. As we did in our example.
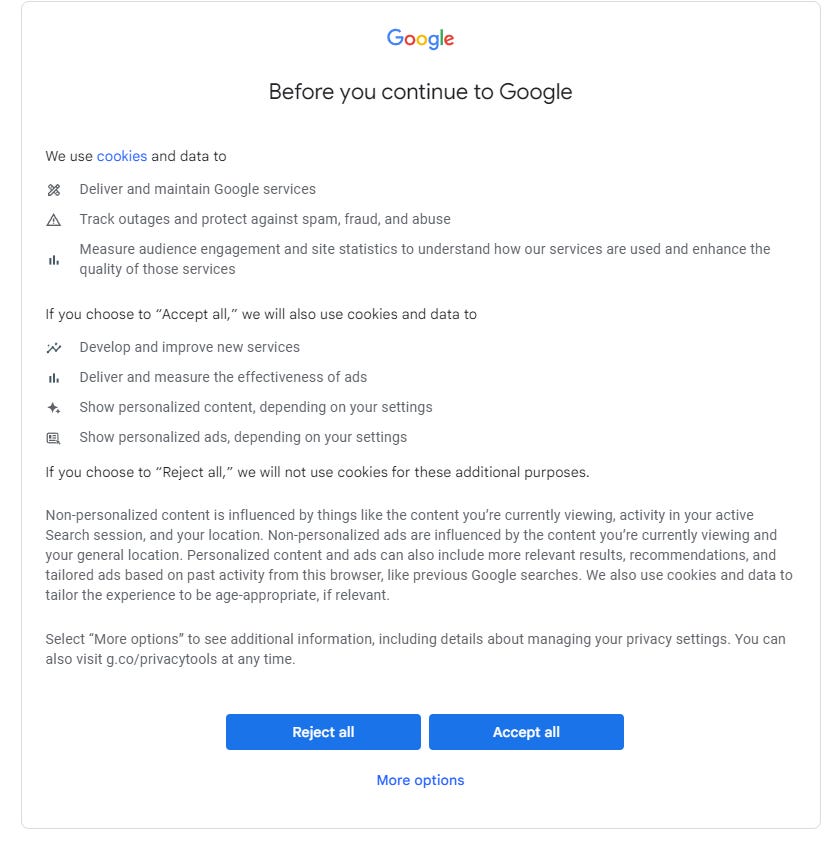
You will notice the driver.find.element which is placed here to bypass the boring Big G Cookie Pop-up. Meaning it will simulate clicking on the “Accept All” automatically. Last but not least we are incorporating the mouse function you will be using directly from the pynput.
Understanding XPath? Hard not to make this topic technical. We recommend further reading on it. Click here for the link.
#C/P the term you want to scrape->niche+location+neighborhood to be precise as possible
url = driver.get('https://www.google.com/maps/search/dentist+in+san+francisco+noe+valley/')
time.sleep(t1)
#This should by default bypass the Google "Cookie Popout". We recommend further reading on xpath and how to inspect elements in your browsers to bypass it. Checkout the provided screen in article
bypass_google_policy = driver.find_element(By.XPATH, '/html/body/c-wiz/div/div/div/div[2]/div[1]/div[3]/div[1]/div[1]/form[2]/div/div/button/span').click()
time.sleep(t1)
#We are setting up mouse function from pynput
mouse = Controller()
This is where things get extremely inefficient in our opinion. First of all, we are selecting the options necessary to open the Instant Data Scraper as well as to click the options we will need to make it work.
What is inefficient about this part is how we repeatedly “open new” leads with the mouse.scroll option. The main idea here was not to make a loop since it might confuse most beginners. Another important point is that we are uncertain about how many leads you will be able to gather based on your input.
When we were playing with this it was enough to have 10 scrolls to make it work. Don’t be afraid to experiment and play with this part of the code.
You could easily make this prettier and more efficient.
#Mouse coridnates pointing to the Extension part of Google Chrome
mouse.position = (1795, 62)
mouse.press(Button.left)
time.sleep(t1)
#Mouse coordinates opening Instant Data Scraper
mouse.position = (1600, 214)
mouse.click(Button.left, 2)
time.sleep(t1)
#Try another table option 1/2
mouse.position = (166, 95)
mouse.click(Button.left, 2)
time.sleep(t1)
#Mark infinite scroll
mouse.position = (51, 168)
mouse.click(Button.left, 1)
time.sleep(t1)
#Add buffer into Instant Data Scraper + importing in the keyboard function with kb
mouse.position = (214, 201)
mouse.click(Button.left, 2)
buffer_to_add = '5'
kb.write(buffer_to_add, 0.1)
time.sleep(t1)
#Click start crawling
mouse.position = (178, 143)
mouse.click(Button.left, 1)
time.sleep(t2)
#Scroll down the lead list for the scraper to grab
mouse.position = (132, 870)
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0,-70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Export to XLSM
mouse.position = (401, 135)
mouse.click(Button.left, 1)
Complete C/P Method #1
Complete code you can c/p.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from pynput.mouse import Controller, Button
import keyboard as kb
import time
driver = webdriver.Chrome()
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ['enable-automation'])
options.add_extension(r'D:\\Coding Projects\\Python_GoogleMaps_Scraping\\instantdatascraper.crx')
driver = webdriver.Chrome(options=options)
driver.maximize_window()
wait = WebDriverWait(driver, 20)
#Marks how much time will it take before "next step". Adjust based on your needs
t1 = 3
t2 = 5
t3 = 10
#C/P the term you want to scrape->niche+location+neighborhood to be precise as possible
url = driver.get('https://www.google.com/maps/search/dentist+in+san+francisco+noe+valley/')
time.sleep(t1)
#This should by default bypass the Google "Cookie Popout". We recommend further reading on xpath and how to inspect elements in your browsers to bypass it. Check out the provided screen in article
bypass_google_policy = driver.find_element(By.XPATH, '/html/body/c-wiz/div/div/div/div[2]/div[1]/div[3]/div[1]/div[1]/form[2]/div/div/button/span').click()
time.sleep(t1)
#We are setting up mouse function from pynput
mouse = Controller()
#Mouse coridnates pointing to the Extension part of Google Chrome
mouse.position = (1795, 62)
mouse.press(Button.left)
time.sleep(t1)
#Mouse coordinates opening Instant Data Scraper
mouse.position = (1600, 214)
mouse.click(Button.left, 2)
time.sleep(t1)
#Try another table option 1/2
mouse.position = (166, 95)
mouse.click(Button.left, 2)
time.sleep(t1)
#Mark infinite scroll
mouse.position = (51, 168)
mouse.click(Button.left, 1)
time.sleep(t1)
#Add buffer into Instant Data Scraper + importing in the keyboard function with kb
mouse.position = (214, 201)
mouse.click(Button.left, 2)
buffer_to_add = '5'
kb.write(buffer_to_add, 0.1)
time.sleep(t1)
#Click start crawling
mouse.position = (178, 143)
mouse.click(Button.left, 1)
time.sleep(t2)
#Scroll down lead list for scraper to grab
mouse.position = (132, 870)
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0,-70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Scroll for more leads
mouse.scroll(0, -70)
time.sleep(t3)
#Export to XLSM
mouse.position = (401, 135)
mouse.click(Button.left, 1)
time.sleep(t2)
print('You are done!')
If you are yet to understand why we call it poor man scraping Google Maps. It’s because we are working around limitations and restrictions with quite an “ineffective method”. But the one that is working.
First of all, you are manipulating the browser to go to Google Maps. The next step will be opening up the Instant Data Scraper and starting to scrape the data - > last part will be downloading the data and cleaning it.
The main idea behind making code so insufficient? To put it as transparent as possible. Making it easy for new guys to manipulate based on their needs.
No one can deny how easy it is to edit this method according to your needs.
Another selling point of the code/automation above is that there is a small chance Google will patch this. Not to say it's impossible. But much harder than in the code you will see below.
What about output?
Will require manual editing. Column names will not make sense. You will see for yourself. Nothing to worry about since it all comes down to logic.
Most Optimal Way To Scrape? Method #2
First of all. This is not our method. Something we stumbled upon while researching our old approach to scraping Google Maps that got patched along the way.
The great thing about this code is how effective it is. You will see its completely different approach using Playwright and Pandas to get things done. You might wonder why we would use Method #1 when we are claiming this is a better way to approach getting leads.
Certain this will get patched in the next 6 months.
Google likes to change small details such as certain paths you will need to make code such as this one work. When it comes to being someone who is starting with scraping it’s not the easiest thing to fix.
The main reason why we are posting a few methods for you to choose.
from playwright.sync_api import sync_playwright
from dataclasses import dataclass, asdict, field
import pandas as pd
import argparse
@dataclass
class Business:
"""holds business data"""
name: str = None
address: str = None
website: str = None
phone_number: str = None
reviews_count: int = None
reviews_average: float = None
@dataclass
class BusinessList:
"""holds list of Business objects,
and save to both excel and csv
"""
business_list: list[Business] = field(default_factory=list)
def dataframe(self):
"""transform business_list to pandas dataframe
Returns: pandas dataframe
"""
return pd.json_normalize(
(asdict(business) for business in self.business_list), sep="_"
)
def save_to_excel(self, filename):
"""saves pandas dataframe to excel (xlsx) file
Args:
filename (str): filename
"""
self.dataframe().to_excel(f"{filename}.xlsx", index=False)
def save_to_csv(self, filename):
"""saves pandas dataframe to csv file
Args:
filename (str): filename
"""
self.dataframe().to_csv(f"{filename}.csv", index=False)
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.google.com/maps", timeout=60000)
# wait is added for dev phase. can remove it in the production
page.wait_for_timeout(5000)
page.locator('//input[@id="searchboxinput"]').fill(search_for)
page.wait_for_timeout(3000)
page.keyboard.press("Enter")
page.wait_for_timeout(5000)
# scrolling
page.hover('//a[contains(@href, "https://www.google.com/maps/place")]')
# this variable is used to detect if the bot
# scraped the same number of listings in the previous iteration
previously_counted = 0
while True:
page.mouse.wheel(0, 10000)
page.wait_for_timeout(3000)
if (
page.locator(
'//a[contains(@href, "https://www.google.com/maps/place")]'
).count()
>= total
):
listings = page.locator(
'//a[contains(@href, "https://www.google.com/maps/place")]'
).all()[:total]
listings = [listing.locator("xpath=..") for listing in listings]
print(f"Total Scraped: {len(listings)}")
break
else:
# logic to break from loop to not run infinitely
# in case arrived at all available listings
if (
page.locator(
'//a[contains(@href, "https://www.google.com/maps/place")]'
).count()
== previously_counted
):
listings = page.locator(
'//a[contains(@href, "https://www.google.com/maps/place")]'
).all()
print(f"Arrived at all available\nTotal Scraped: {len(listings)}")
break
else:
previously_counted = page.locator(
'//a[contains(@href, "https://www.google.com/maps/place")]'
).count()
print(
f"Currently Scraped: ",
page.locator(
'//a[contains(@href, "https://www.google.com/maps/place")]'
).count(),
)
business_list = BusinessList()
# scraping
for listing in listings:
listing.click()
page.wait_for_timeout(5000)
name_xpath = '//div[contains(@class, "fontHeadlineSmall")]'
address_xpath = '//button[@data-item-id="address"]//div[contains(@class, "fontBodyMedium")]'
website_xpath = '//a[@data-item-id="authority"]//div[contains(@class, "fontBodyMedium")]'
phone_number_xpath = '//button[contains(@data-item-id, "phone:tel:")]//div[contains(@class, "fontBodyMedium")]'
reviews_span_xpath = '//span[@role="img"]'
business = Business()
if listing.locator(name_xpath).count() > 0:
business.name = listing.locator(name_xpath).inner_text()
else:
business.name = ""
if page.locator(address_xpath).count() > 0:
business.address = page.locator(address_xpath).inner_text()
else:
business.address = ""
if page.locator(website_xpath).count() > 0:
business.website = page.locator(website_xpath).inner_text()
else:
business.website = ""
if page.locator(phone_number_xpath).count() > 0:
business.phone_number = page.locator(phone_number_xpath).inner_text()
else:
business.phone_number = ""
if listing.locator(reviews_span_xpath).count() > 0:
#business.reviews_average = float(
#listing.locator(reviews_span_xpath)
#.get_attribute("aria-label")
#.split()[0]
#.replace(",", ".")
#.strip()
#)
#business.reviews_count = int(
#listing.locator(reviews_span_xpath)
#.get_attribute("aria-label")
#.split()[2]
#.strip()
#)
#else:
#business.reviews_average = ""
#business.reviews_count = ""
business_list.business_list.append(business)
# saving to both excel and csv just to showcase the features.
business_list.save_to_excel("Put your path.xlsx")
business_list.save_to_csv("Put your path.csv")
browser.close()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-s", "--search", type=str)
parser.add_argument("-t", "--total", type=int)
args = parser.parse_args()
if args.search:
search_for = args.search
else:
# in case no arguments passed
# the scraper will search by defaukt for:
search_for = "coffee places San Francisco"
# total number of products to scrape. Default is 10
if args.total:
total = args.total
else:
total = 100 # edit based on your needs
main()
As you can see this code is much more complex when you compare it with ours.
Pay attention to:
In case you got hit with cookie popout (check Method #1 again). Import selenium into the code from above and c/p .click() line to make it work. Better option? Learn to bypass it using imported libraries it’s possible.
Review ratings are off - commented with # as you can see.
Make sure to add paths into save_to_excel and save_to_csv. The location where your scrape will go.
The search term is at the end of the code as well as how many leads you want to grab. Tailor it towards your needs.
All the credit to the original author can be found on GitHub.
Don’t Have Time But Need Scrape? Method #3
Scrape with API.
Simple as that. This is by far the easiest way you will scrape local leads from Google Maps. Unfortunately, the process is somehow different depending on the API you are about to use. Easiest in comparison with the other two“methods”.
We are not going to go fully into the details here. But take a look at the code below. Night and day difference.
Comparison-wise this is the Google Maps Python scraping with API.
from sc_google_maps_api import (your API provider libary)
client = Your API provider(api_key='INSERT_YOUR_API_KEY_HERE')
response = client.scrape(
params={
"keyword": "cafe in new york",
"country": "US",
"domain": "com"
}
)
print(response.text)
Only negative aspect of it?
You will be required to pay a minimum of $40 per month. Depending on the package and the number of leads you plan to scrape. All will come down to your needs and goals. What you could do if you are unsure…
Make a bunch of trial accounts and a few variations of the code you will run (API part). Should be easy to “abuse” the providers while at the same time getting yourself quite a few “free leads”.
Need example?
The following page is giving you 1000 free credits for the first 30 days. Think about the bigger picture here. The game plan is following:
Create yourself free trial accounts
Create a script based on the API they will provide you with
Use credits/points
Create new trial accounts
Throw them in already-made scripts
Repeat
Should be pretty straightforward.
Leaving you with a few good links you can check and use to your advantage.
The first article is done when it comes to Python. We are 100% certain there will be an update of this article down the road. Once we find a more optimal approach to tackle scraping Google Maps.
As you already know how it works with our content. You will be updated.
Until then things should be pretty straightforward as we tried to keep it as simple as possible. Depending on your goals you will have few options. Clean the scrape and sell it or use it in your outreach.
Completly depends on you.
If you have questions about a specific part or need help with the code. DM us on the Twitter app or comment on the post. We will try to assist and help you as much as possible.





You will have to find something that others find valuable. Scrap it -> sell it. Forums are a good place to start.
Thanks , it's all good , but now how can I find clients for it ?? Simply how can I earn with this skill ?